CantoTalk: Probing Teacher Expertise From Fine-Tuned Representations
Fine-tuned five LLMs on 7,518 Cantonese teacher utterances to classify talk moves (micro-F1=0.81). Probed embeddings to show teacher expertise is linearly separable and clustering reveals three distinct discourse styles.
Classroom discourse profoundly shapes learning, but analyzing teacher talk at scale is hard in non-Western, low-resource language contexts. Most research focuses on English-speaking classrooms, missing how pedagogical moves adapt cross-culturally. We introduced CantoTalk—7,518 Cantonese teacher utterances from Hong Kong math classrooms—and investigated whether fine-tuned LLMs can classify talk moves and encode teacher expertise.
What’s in it
CantoTalk annotates 10 talk-move categories (revoicing, pressing, probing, etc.) from Hong Kong mathematics classrooms. We fine-tuned five open-weight LLMs for classification, then probed whether learned embeddings encode systematic differences in teacher expertise.
Approach
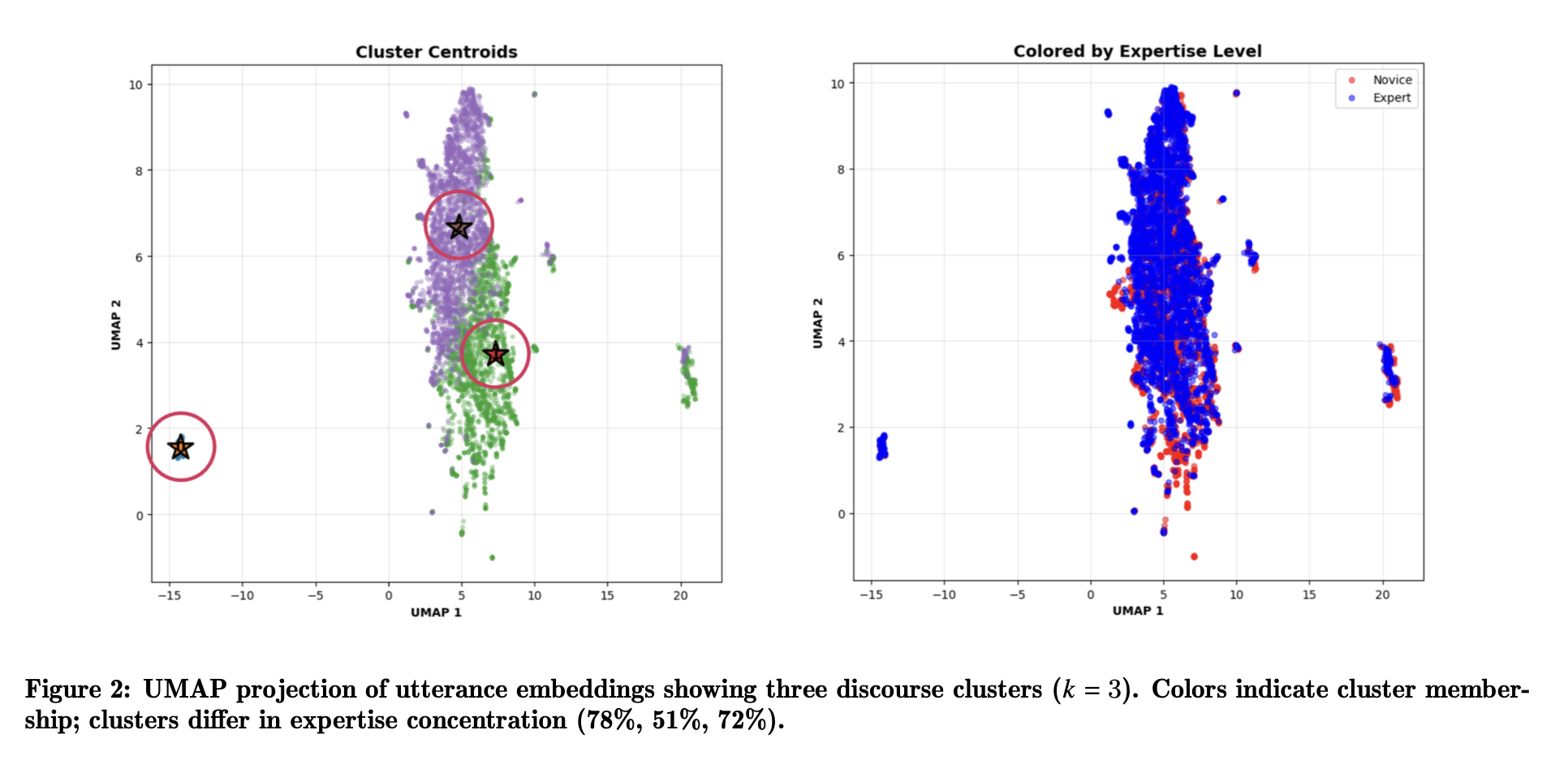
Fine-tuned five LLMs on talk move classification, extracted utterance-level embeddings, then tested whether expert vs. novice teachers are separable in representation space using linear probes. Clustering revealed discourse styles, with qualitative analysis showing how experienced and novice teachers execute similar moves differently.
Results
Best model (Qwen3-8B) achieved micro-F1 = 0.81, macro-F1 = 0.77. Teacher expertise is linearly separable from embeddings with balanced accuracy = 0.79, well above chance even after controlling for surface features. Clustering revealed three coherent discourse styles: authoritative (high control), scaffolding (structured support), dialogic (distributed authority). Experienced teachers show greater scaffolding precision and dialogic flexibility.
Why it matters
Fine-tuned LLM representations capture meaningful pedagogical signal beyond surface patterns—they encode systematic differences in expertise. This opens new possibilities for analyzing classroom discourse at scale, especially in low-resource languages where manual coding is infeasible. Rather than treating LLMs as black boxes, we show their learned representations reveal structured pedagogical knowledge—useful not just for classification but for understanding what distinguishes expert teaching.