A Bigger Catch: Fine-Grained Curriculum Alignment on MathFish
Built a three-stage pipeline (hard negatives, cross-encoder reranking, ReAct agent) to predict which of 385 Common Core standards a math problem aligns to, achieving 31.3% exact match (6.5× baseline). Accepted at 21st BEA @ ACL 2026.
Most math benchmarks for LLMs ask one question: can the model get the right answer? But in actual K-12 education, understanding what a problem teaches matters as much as solving it. Professional curriculum reviewers spend months mapping problems to fine-grained pedagogical standards—385 of them in Common Core alone. We built a pipeline to see if LLMs can do this tagging reliably.
What we built
A three-stage system tested on the MathFish benchmark:
- M1: Hard negative mining with curriculum-informed distractors
- M2: Cross-encoder re-ranker for structural reasoning
- M3: ReAct agent + LLM-as-judge critic for deliberative multi-step reasoning
Plus a training-free alternative (A1) using hybrid sparse-dense retrieval with curriculum graph reranking.
Approach
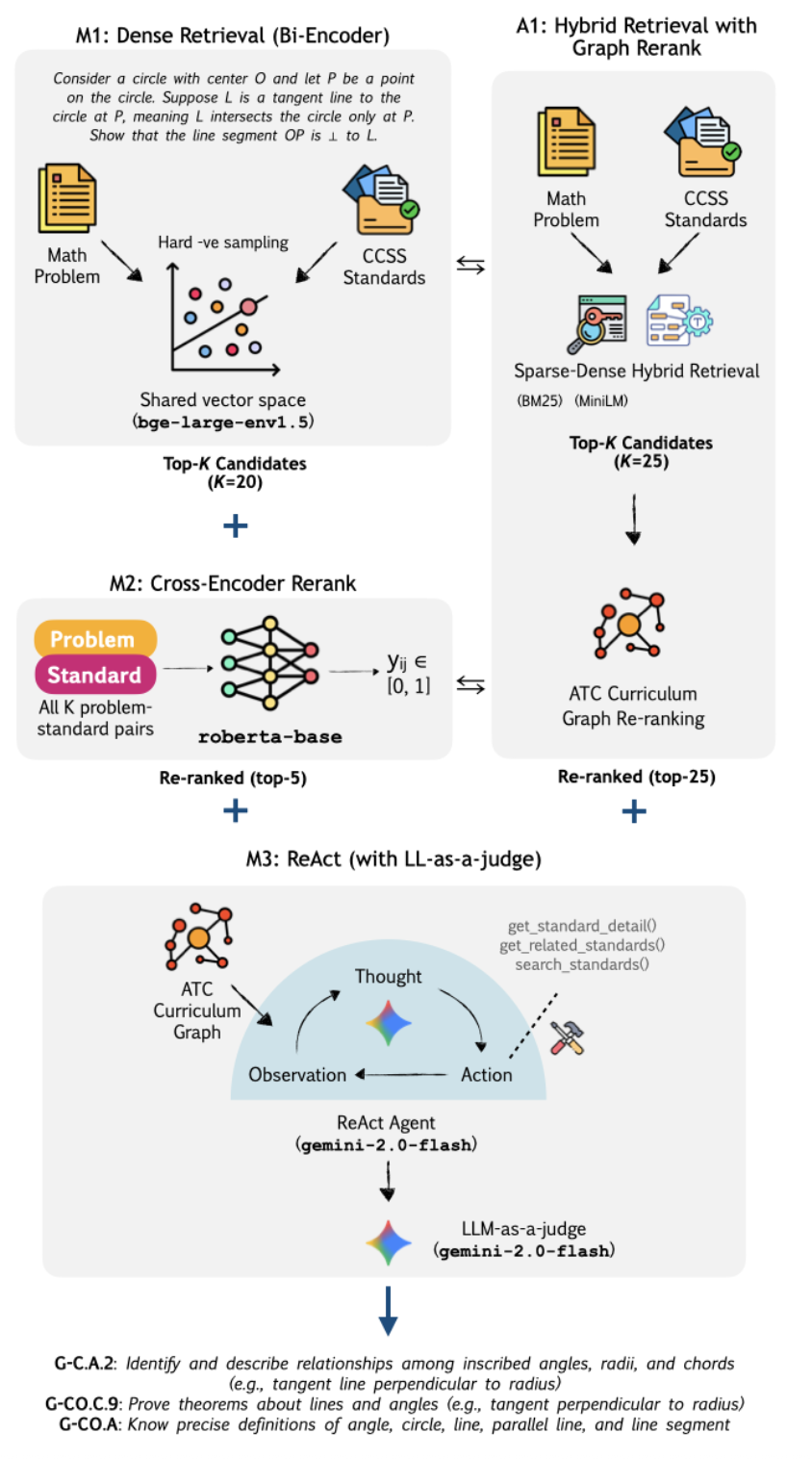
Each stage tackles a specific failure mode: retrieval confounds (surface similarity misleads), structural gaps (hierarchy ignored), shallow prediction (no multi-step deliberation). The ReAct agent iteratively reasons over curriculum structure with critic feedback.
Results
M3 hits 31.3% exact match—roughly 6.5× the three-shot GPT-4-Turbo baseline. Biggest gains come from deliberative reasoning (the agent + critic). But persistent challenges remain: missing predictions, grade-level confusion (K vs. Grade 1), sibling standard mix-ups.
Why it matters
This shows precise curriculum alignment is genuinely hard—even sophisticated pipelines leave room for improvement. Educational benchmarks can’t just measure correctness; they need to capture pedagogical structure. That requires reasoning over hierarchical taxonomies and understanding subtle instructional distinctions. As LLMs generate assessments and tag curriculum content, knowing what a problem teaches becomes as critical as solving it.