Psychometric Analysis of MRBench V2
Applied CFA, IRT, G-theory, and measurement invariance testing to validate MRBench V2. Found six of eight dimensions form a coherent scale (CFI=0.998, Grel=0.974) but detected non-equivalence across model sizes.
Educational AI benchmarks are increasingly used to evaluate LLM tutors, but their psychometric properties rarely get examined. That matters because benchmarks are measurement instruments—and without validation, we don’t know if they measure what they claim, whether scores are reliable, or if cross-model comparisons are even meaningful. We applied a comprehensive psychometric pipeline to MRBench V2.
What we did
Full psychometric validation of MRBench V2 (200 tutoring dialogues, 8 pedagogical dimensions, 7 LLMs + 2 human tutors) using six methods:
- Exploratory Factor Analysis — uncover latent structure
- Confirmatory Factor Analysis — test structural fit
- Graded Response Modelling (IRT) — item-level diagnostics
- Measurement invariance testing — cross-group comparability
- Generalizability theory — reliability decomposition
- Validity diagnostics — construct and predictive validity gaps
Approach
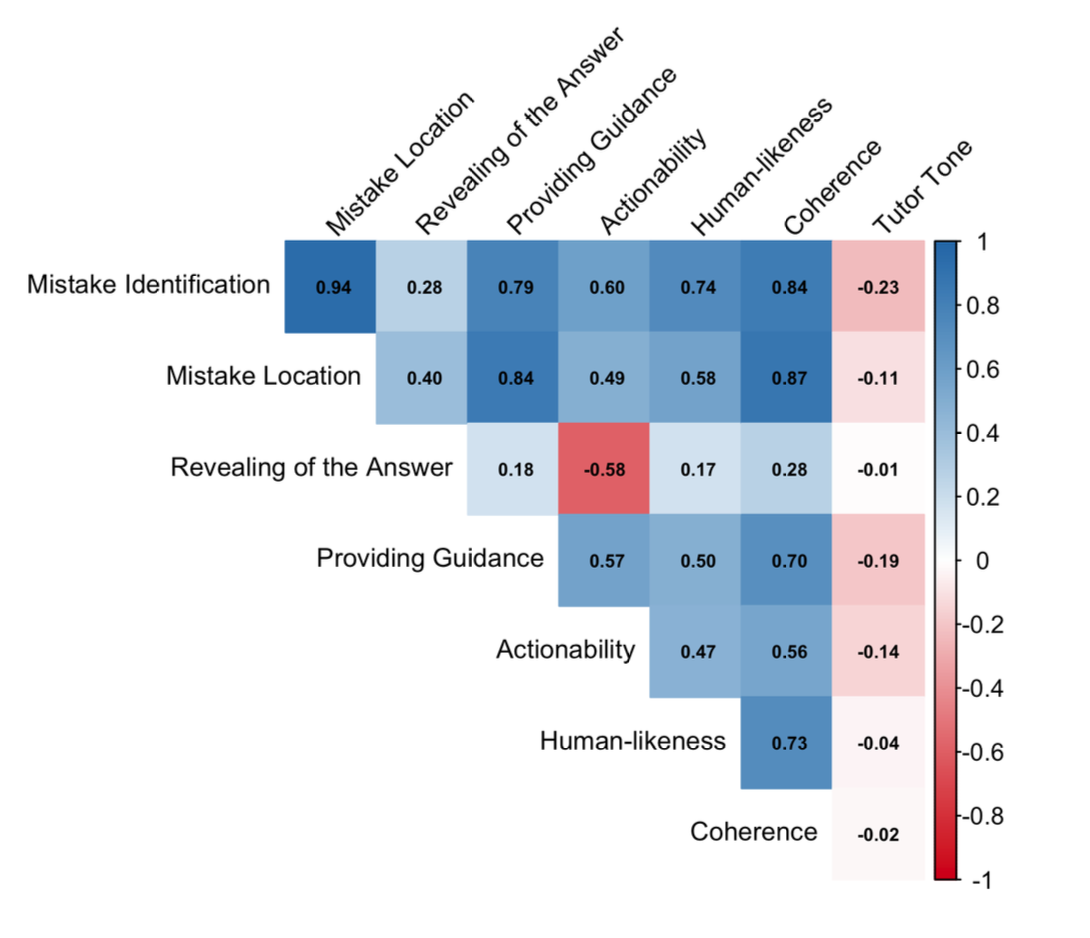
Started by uncovering latent structure, then tested whether the claimed eight-dimension taxonomy holds. IRT evaluated whether individual dimensions function as intended. Invariance testing checked if small vs. large models are measured on the same scale. G-theory decomposed reliability sources. Validity diagnostics probed construct alignment and outcome prediction.
Results
Six of eight dimensions form a coherent unidimensional scale with excellent fit (CFI = 0.998, RMSEA = 0.058) and strong reliability (Grel = 0.974). Two dimensions show properties inconsistent with their intended role. We detected measurement non-equivalence across model sizes—small vs. large models may not be on the same scale, so cross-tier comparisons need caution. Open questions remain about what the construct actually measures and whether it predicts learning outcomes.
Why it matters
Psychometric validation should be standard practice in educational AI benchmarking. Without it, we risk using benchmarks that don’t measure what they claim, making invalid cross-model comparisons, or optimizing for metrics that lack construct validity. These methods—CFA, IRT, invariance testing, G-theory—come from educational testing’s century-long tradition. As LLM tutors scale into classrooms, knowing our evaluation instruments are psychometrically sound becomes essential.